V-MAGE Evaluation Pipeline.
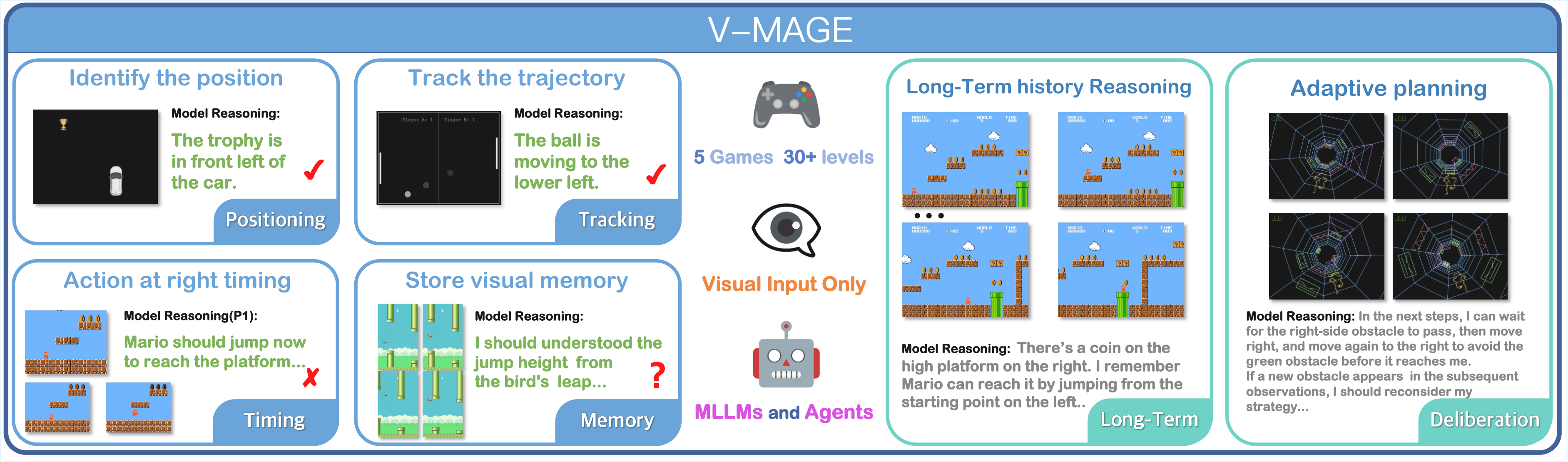
We selected five different games and designed several levels for each game to decompose the evaluation of model performance.
The games used are FlappyBird, RaceGame, SuperMario, PongGame, and Tempest Run.
During the evaluation process, the Agent module receives visual game state information from the Game module, specifically in the form of game screenshots. Within the Agent module, these screenshots are structured into inputs for the model.
In the baseline agent of V-MAGE, inputs to the MLLM models are constructed by combining screenshots from the most recent three frames with a prompt containing the game rules.
The output of the model is processed by the Agent module into response actions, which are subsequently sent back to the Game module.

OpenAI GPT-4o

Google Gemini 2.0 Flash

Qwen2.5VL-72B

OpenAI GPT-4o

Google Gemini 2.0 Flash

Qwen2.5VL-72B

OpenAI GPT-4o

Google Gemini 2.0 Flash

Qwen2.5VL-72B
Game playing examples of MLLMs sampled from the evaluation process in V-MAGE.
Performance comparison across different games based on the ELO ranking system. The Random baseline refers to randomly selecting actions from the predefined action space during decision-making phases. Avg. Ratio refers to the average percentage of the model's score compared to the human baseline score.
| Model | Flappybird | Pong | Race | Supermario | Tempestrun | Avg. ELO Score | Avg. Ratio (%) |
|---|---|---|---|---|---|---|---|
| Closed-Source Models | |||||||
| GPT-5-2025-08-07 | 1572 | 1939 | 1710 | 1584 | 1743 | 1710 | 43.4 |
| Gemini-2.5-Pro | 1526 | 1602 | 1660 | 1758 | 1474 | 1604 | 36.3 |
| Claude-3.7-Sonnet | 1560 | 1570 | 1633 | 1582 | 1369 | 1543 | 30.8 |
| Gemini-2.5-Flash | 1578 | 1524 | 1520 | 1531 | 1489 | 1528 | 23.8 |
| GPT-4o | 1557 | 1449 | 1581 | 1518 | 1527 | 1526 | 26.6 |
| Gemini-2.0-Flash (Thinking) | 1517 | 1479 | 1503 | 1564 | 1516 | 1516 | 22.6 |
| GPT-5.1-2025-11-13 | 1552 | 1514 | 1507 | 1449 | 1411 | 1486 | 20.1 |
| Gemini-2.0-Flash | 1494 | 1461 | 1437 | 1499 | 1530 | 1484 | 16.7 |
| Open-Source Models | |||||||
| Qwen3-VL-235B-A22B-Instruct | 1567 | 1441 | 1517 | 1556 | 1496 | 1515 | 24.3 |
| Qwen2.5-VL-72B-Instruct | 1556 | 1442 | 1506 | 1541 | 1530 | 1515 | 22.8 |
| InternVL2.5-78B | 1463 | 1462 | 1465 | 1543 | 1528 | 1492 | 19.2 |
| Qwen2-VL-72B-Instruct | 1426 | 1445 | 1442 | 1505 | 1547 | 1473 | 16.5 |
| InternVL2.5-8B | 1459 | 1448 | 1431 | 1373 | 1495 | 1441 | 12.9 |
| Qwen2.5-VL-7B-Instruct | 1457 | 1446 | 1423 | 1354 | 1517 | 1439 | 12.1 |
| Qwen2-VL-7B-Instruct | 1470 | 1447 | 1408 | 1362 | 1501 | 1438 | 11.4 |
| Keye-VL-8B-Preview | 1419 | 1444 | 1428 | 1381 | 1499 | 1434 | 13.1 |
| Phi-4-multimodal-instruct | 1404 | 1454 | 1420 | 1482 | 1385 | 1429 | 13.7 |
| Baseline | |||||||
| Random | 1422 | 1434 | 1410 | 1417 | 1445 | 1426 | 11.0 |
@article{zheng2025vmagebenchmark,
title={V-MAGE: A Game Evaluation Framework for Assessing Visual-Centric Capabilities in Multimodal Large Language Models},
author={Xiangxi Zheng and Linjie Li and Zhengyuan Yang and Ping Yu and Alex Jinpeng Wang and Rui Yan and Yuan Yao and Lijuan Wang},
journal={arXiv preprint arXiv:2504.06148},
year={2025}
}