People See Text, But LLM Not
“Aoccdrnig to a rscheearch at Cmabrigde Uinervtisy, it deosn't mttaer in waht oredr the ltteers in a wrod are.” — Davis, Matt (2012)
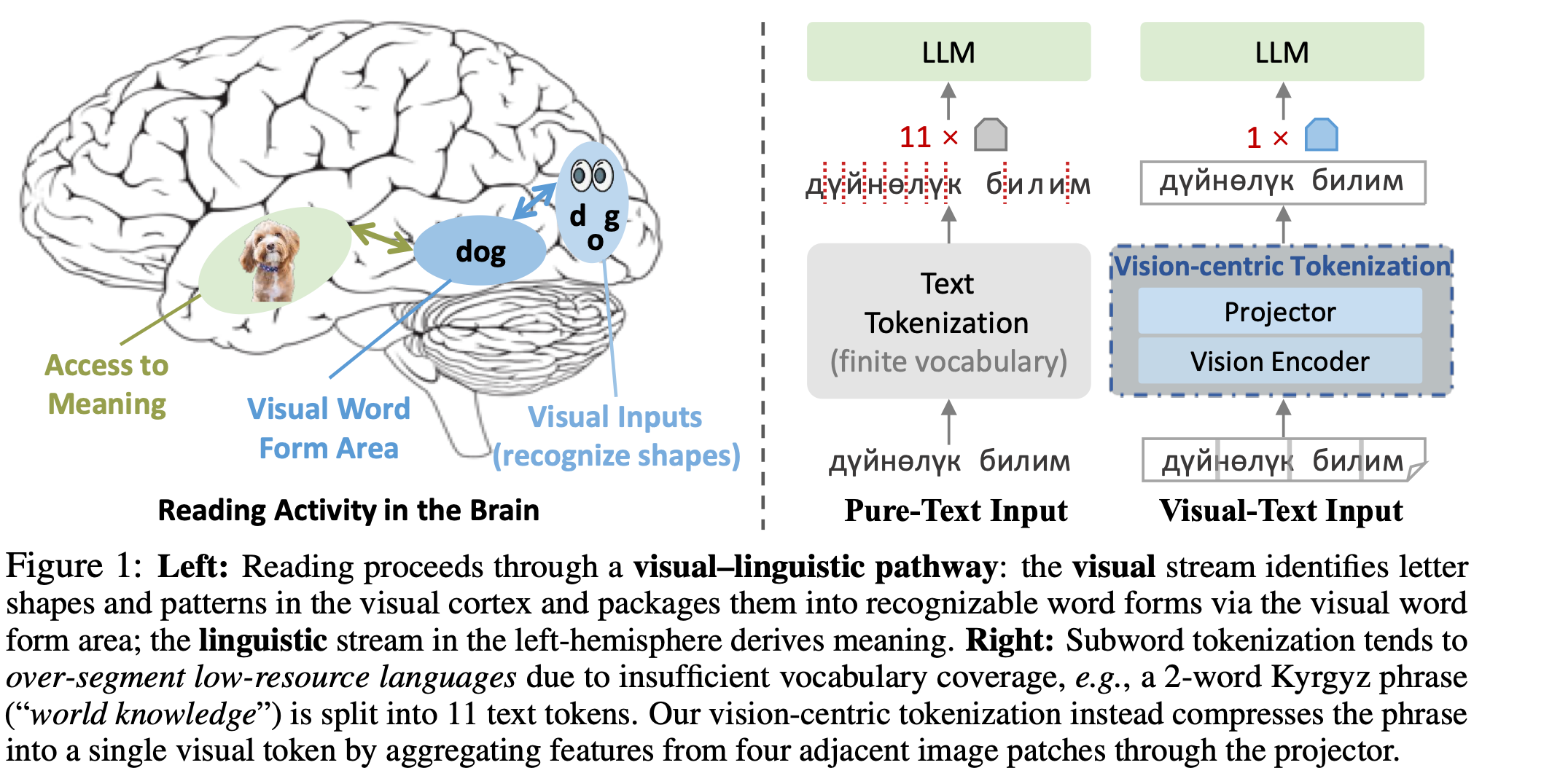
You can probably read that sentence effortlessly. Despite the chaotic order of letters, your brain automatically reconstructs the intended words — because humans don’t read text letter by letter. We perceive shapes, patterns, and visual words.
1. See Text vs. LLM Process Text
1.1 The Visual Nature of Reading
Cognitive neuroscience has long shown that our brain recruits a specialized region called the Visual Word Form Area (VWFA) in the left occipitotemporal cortex. This area recognizes entire word forms as visual objects, not symbolic sequences. That’s why humans can read “Cmabrigde” as Cambridge, or identify words in distorted fonts, mixed scripts, and complex layouts.
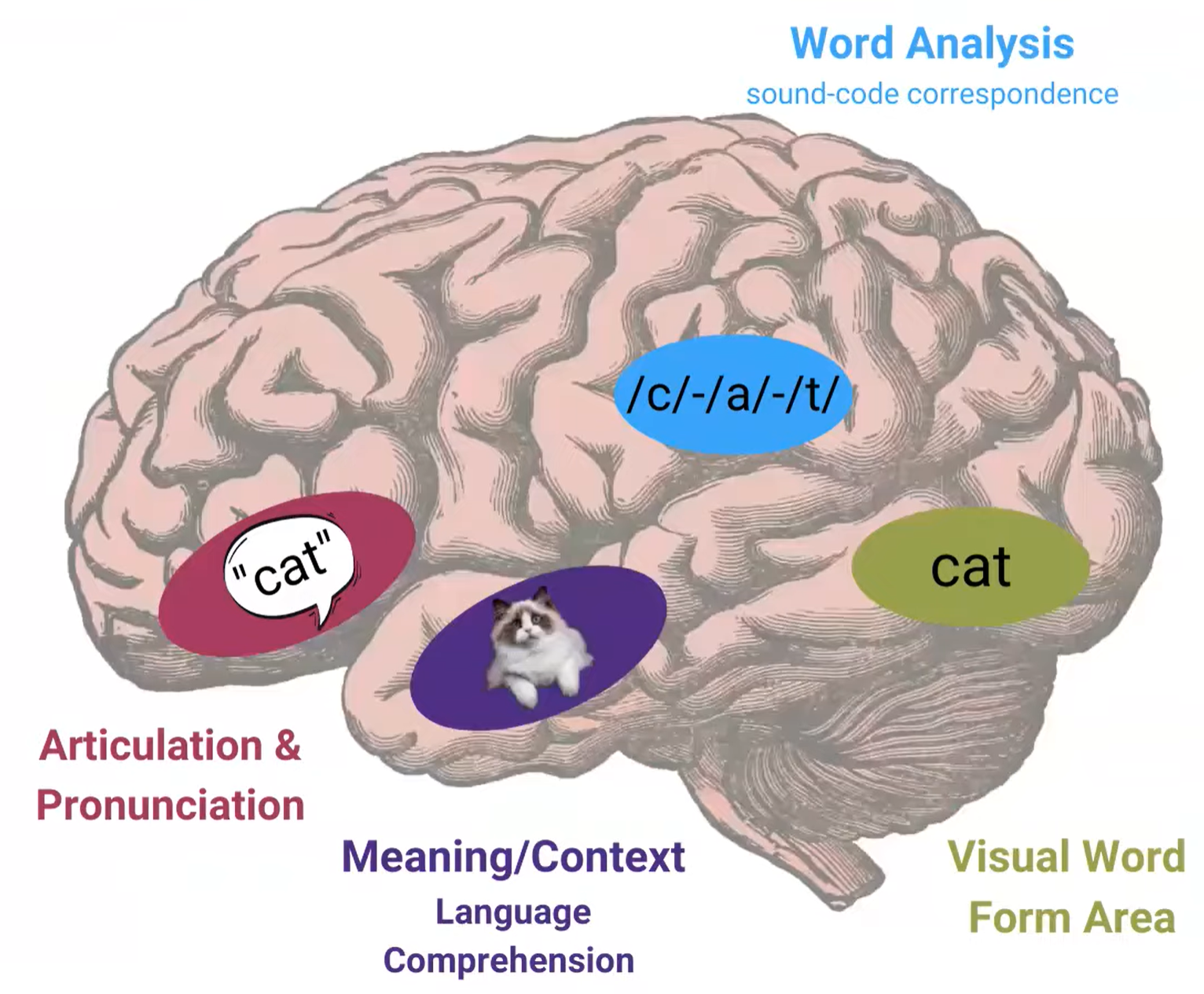
In essence, people see text. Reading is vision — not just language processing.
1.2 How LLMs Process Text (and Why It’s Different)
Large Language Models (LLMs), in contrast, do not “see” text. They tokenize it — breaking sentences into subword units like “vis”, “ion”, “cent”, “ric”. Each token becomes an integer ID looked up in a vocabulary. This is efficient for symbolic computation, but it destroys the visual and structural continuity of language. As a result, the holistic form of text is lost in translation. Humans can easily read “t3xt” as “text,” but token-based models treat them as unrelated sequences.
1.3 The Consequences of Tokenization
- Loss of visual semantics: Fonts, shapes, and layout cues disappear.
- Over-segmentation in multilingual text: Low-resource languages get fragmented into meaningless subwords.
- Inefficiency for long text: A few characters can turn into multiple tokens, inflating context length and cost.
This is why a model might read a paper or screenshot yet miss equations, tables, or captions — because they are treated as pixels, not text.
1.4 Text Widely Exists in Web Images
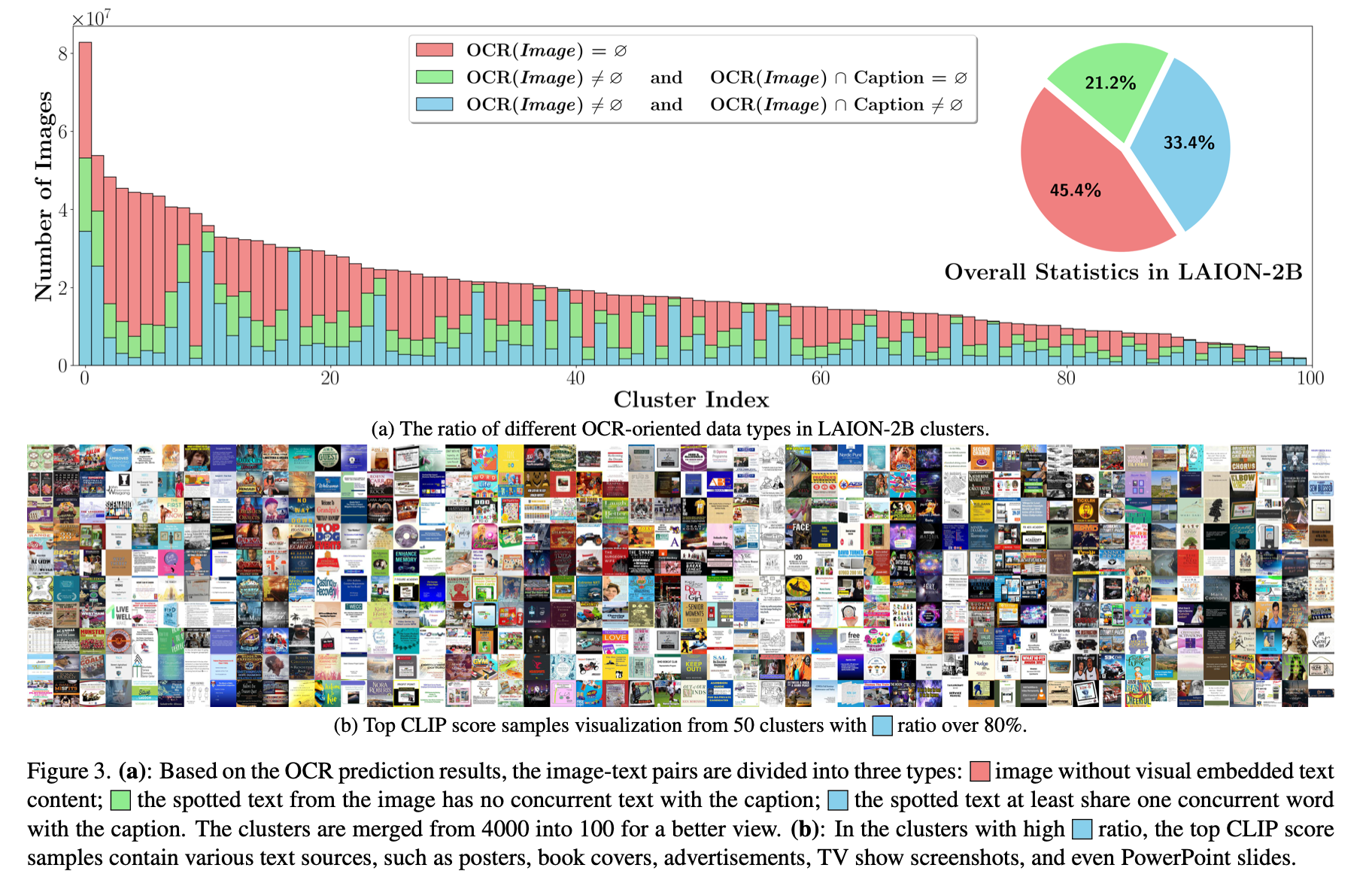
45%+ web images contain text (e.g., in LAION-2B; Lin et al., Parrot, ECCV 2024). Documents, UI, charts, and designs are inherently visual text.
2. Early Attempts: Making Models See Text / Unified Model
Several early studies tried to bridge this gap by treating text as an image signal:
- Visual Text Representations (Salesky et al., EMNLP 2021): The paper introduces visual text representations that replace discrete subword vocabularies with continuous embeddings derived from rendered text. This method matches traditional models in translation quality while being far more robust to noisy or corrupted input.
- PIXEL (Phillip et al., ICLR 2023): render text as images, pretrain ViT-MAE to reconstruct masked pixels, removing the tokenizer; robust to unseen scripts and orthographic perturbations.
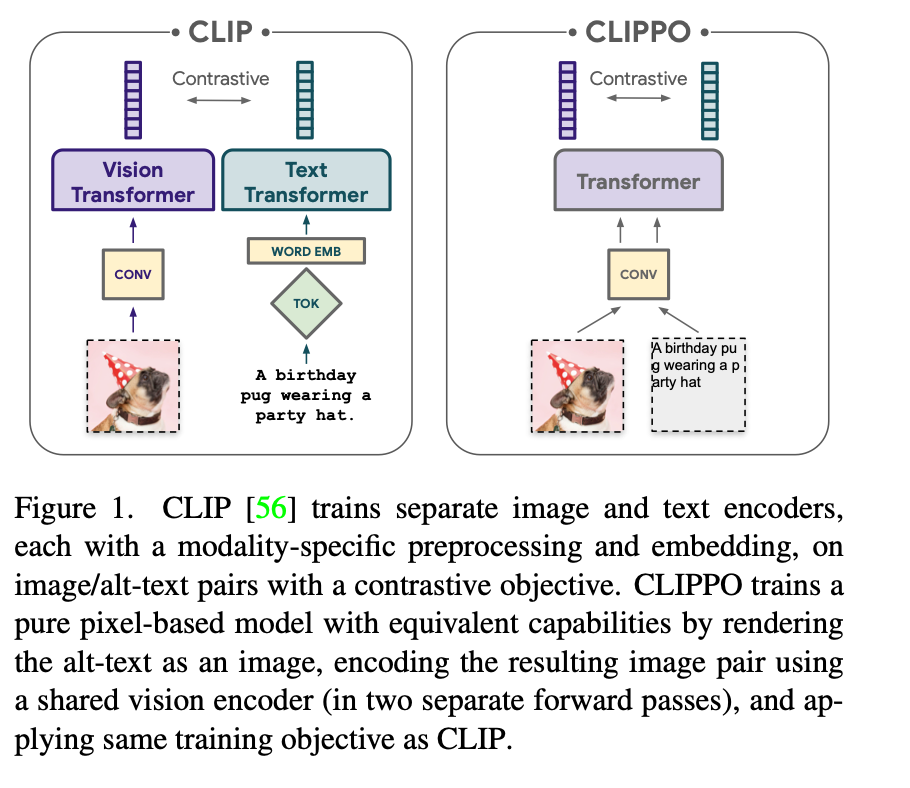
- CLIPPO (Michael et al., CVPR 2023): unify image & text under a single pixel-based encoder; text is rendered to images and trained with contrastive loss.
- Pix2Struct (Lee et al., ICML 2023): parse screenshots as structured visual input for document/layout understanding.
- PIXAR(Tai et al., ACL 2024): PIXAR is pixel-based autoregressive LLM capable of generating readable text, using adversarial pretraining to overcome MLE limitations and reach GPT-2-level performance. .
- PTP (Gao et al., arXiv 2024): screenshot language models with a Patch-and-Text Prediction objective to reconstruct masked image patches and text jointly.
- PEAP (Lyu et al., arXiv 2025'): a unified perception paradigm for agentic language models that interact directly with real-world environments combining visual and textual information.

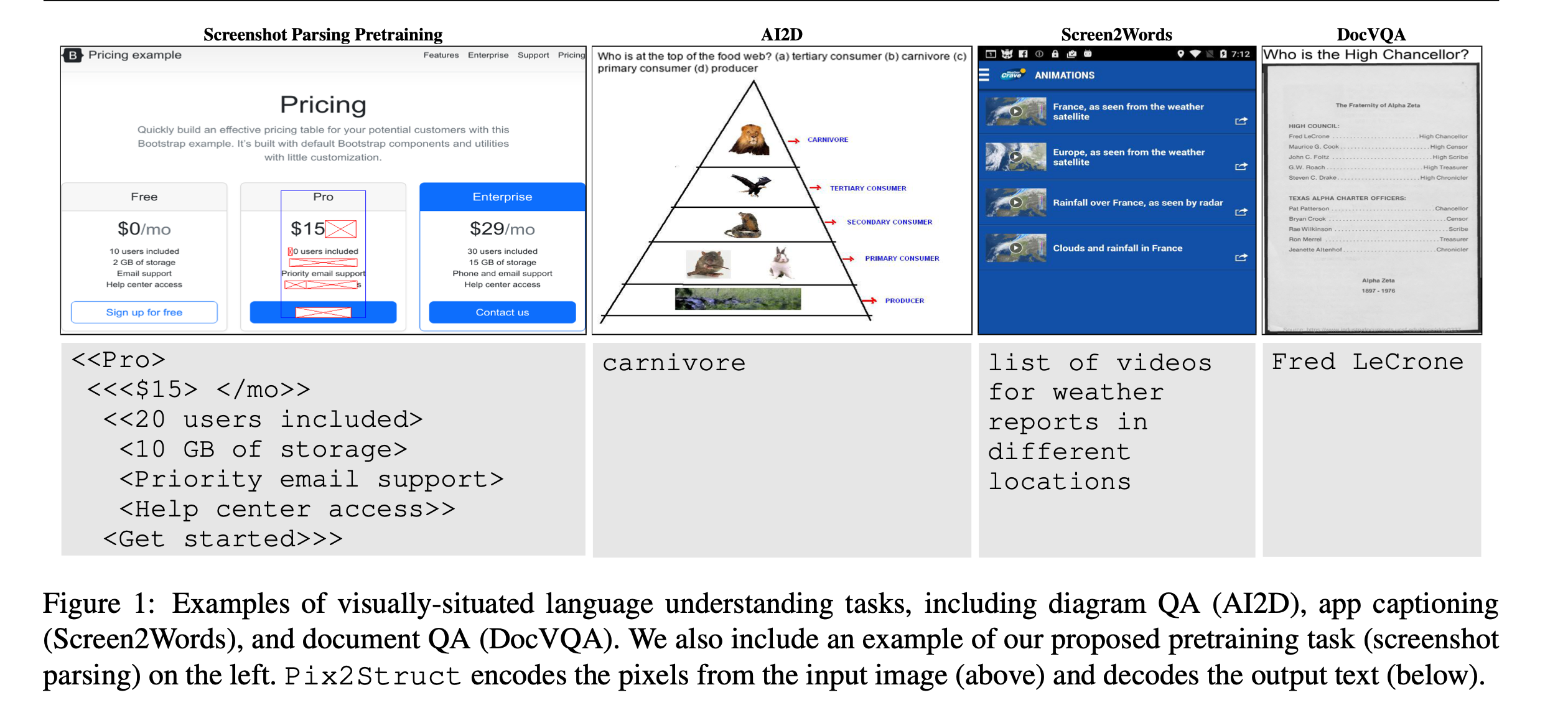
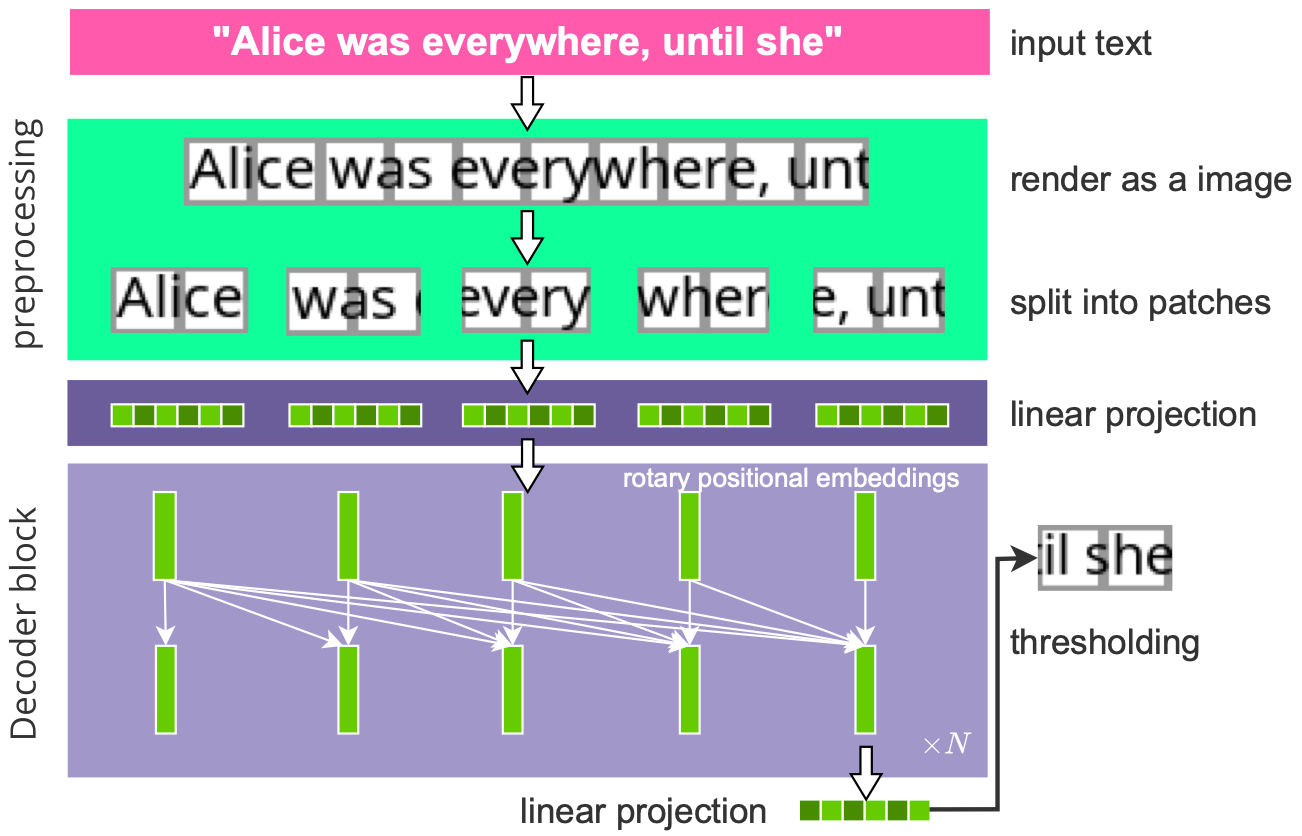
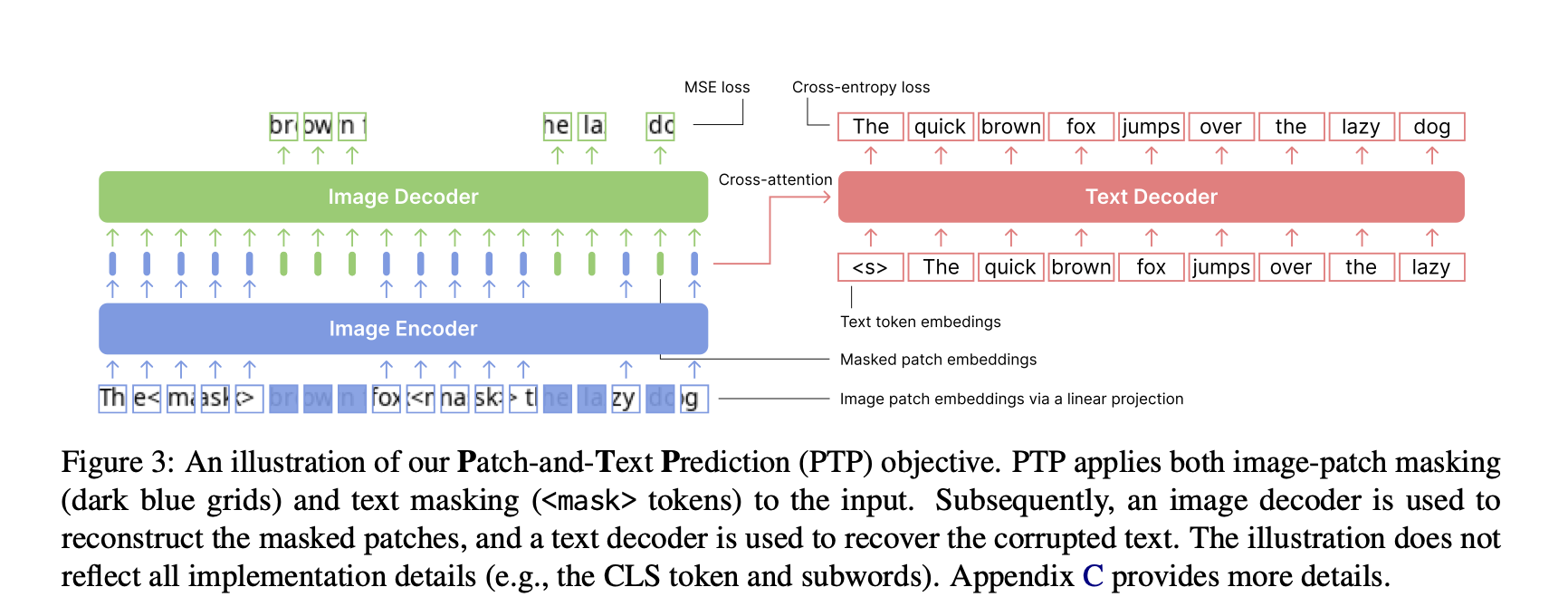
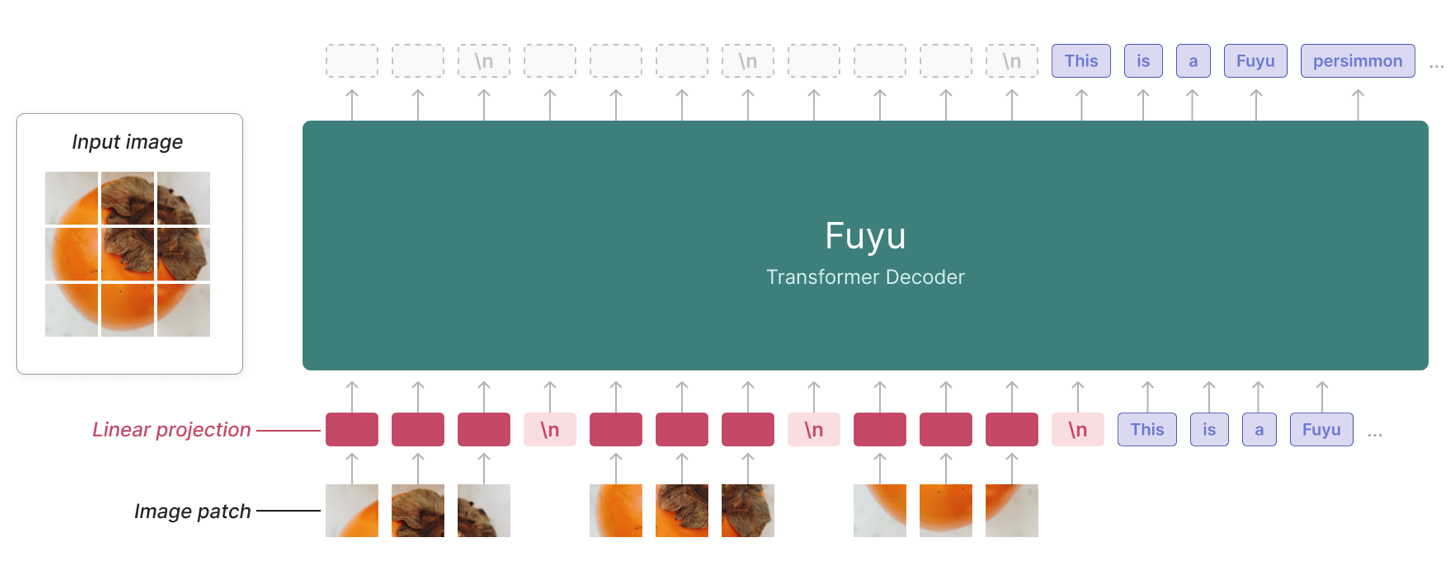
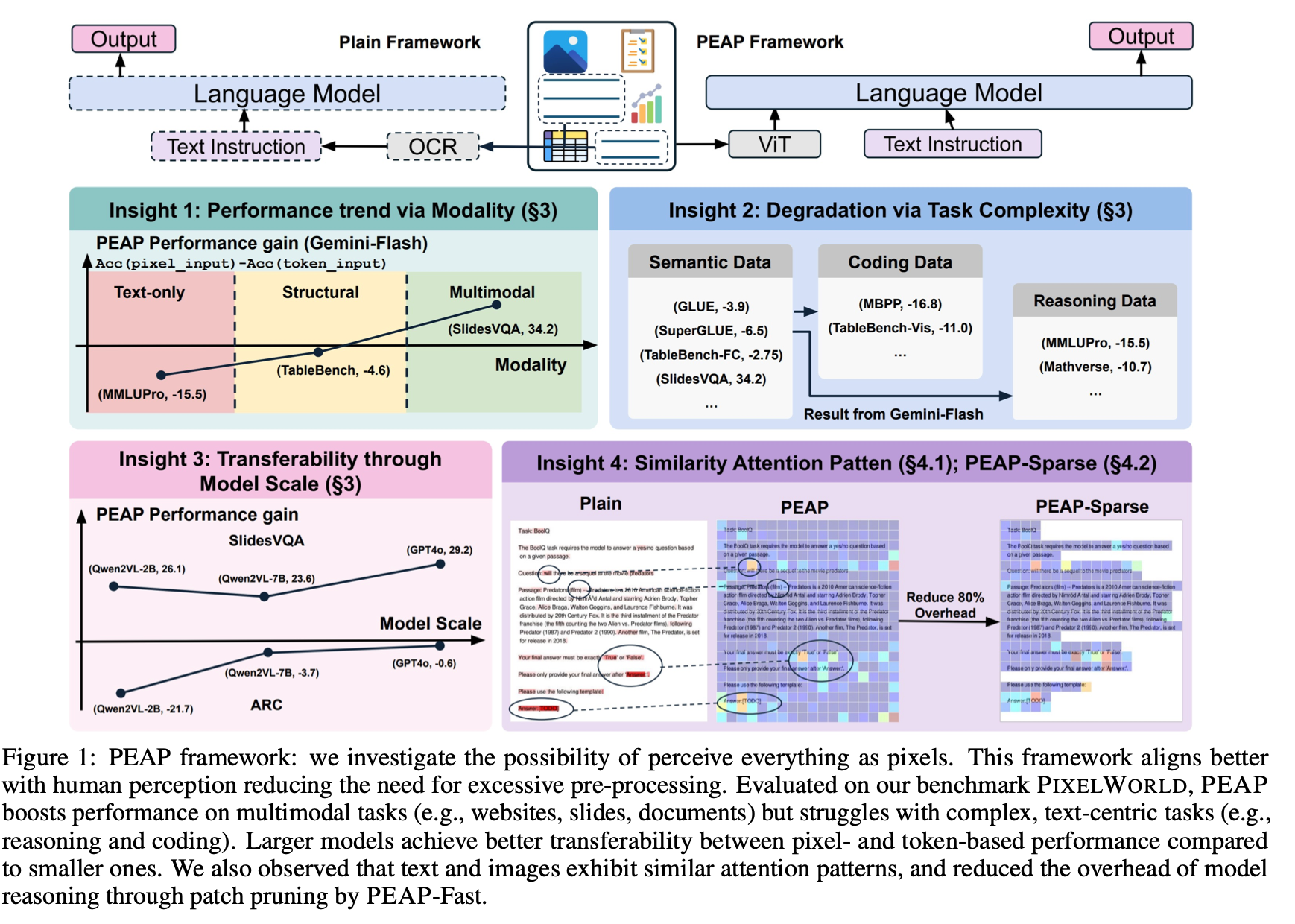
These works helped models see text, but left a key question: what tangible benefit does transforming text into images actually provide?
3. Recent Attempts: Visual Tokens for Long-Context Compression
Key observations:
- 1. Vision encoders are typically much smaller than LLMs (e.g., ~100M for ViT-B vs. 7B+ for LLaMA/Mistral).
- 2. CLIP-style pretraining yields emergent OCR-like abilities without explicit supervision.
- 3. Visual patches can encode dense textual content (more characters per spatial area), effectively extending context via spatial compression.
Interleaved document-level multimodal pretraining is an ideal setup.
NeurIPS 2024 — “Leveraging Visual Tokens for Extended Text Contexts”: represent long text as compact visual tokens, enabling longer & denser context at training and inference.
This improves in-context text length from 256 → 2048 during pretraining on NVIDIA H100.
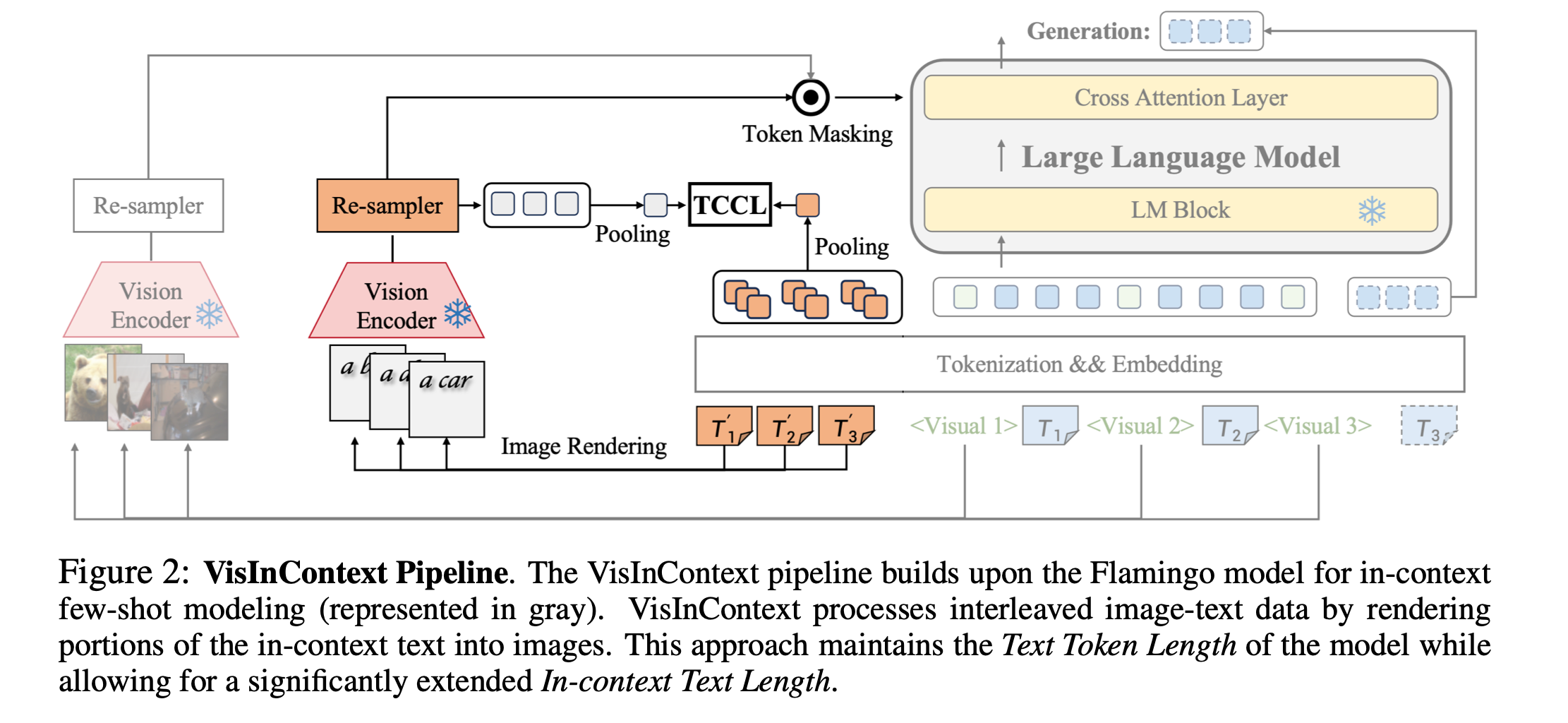
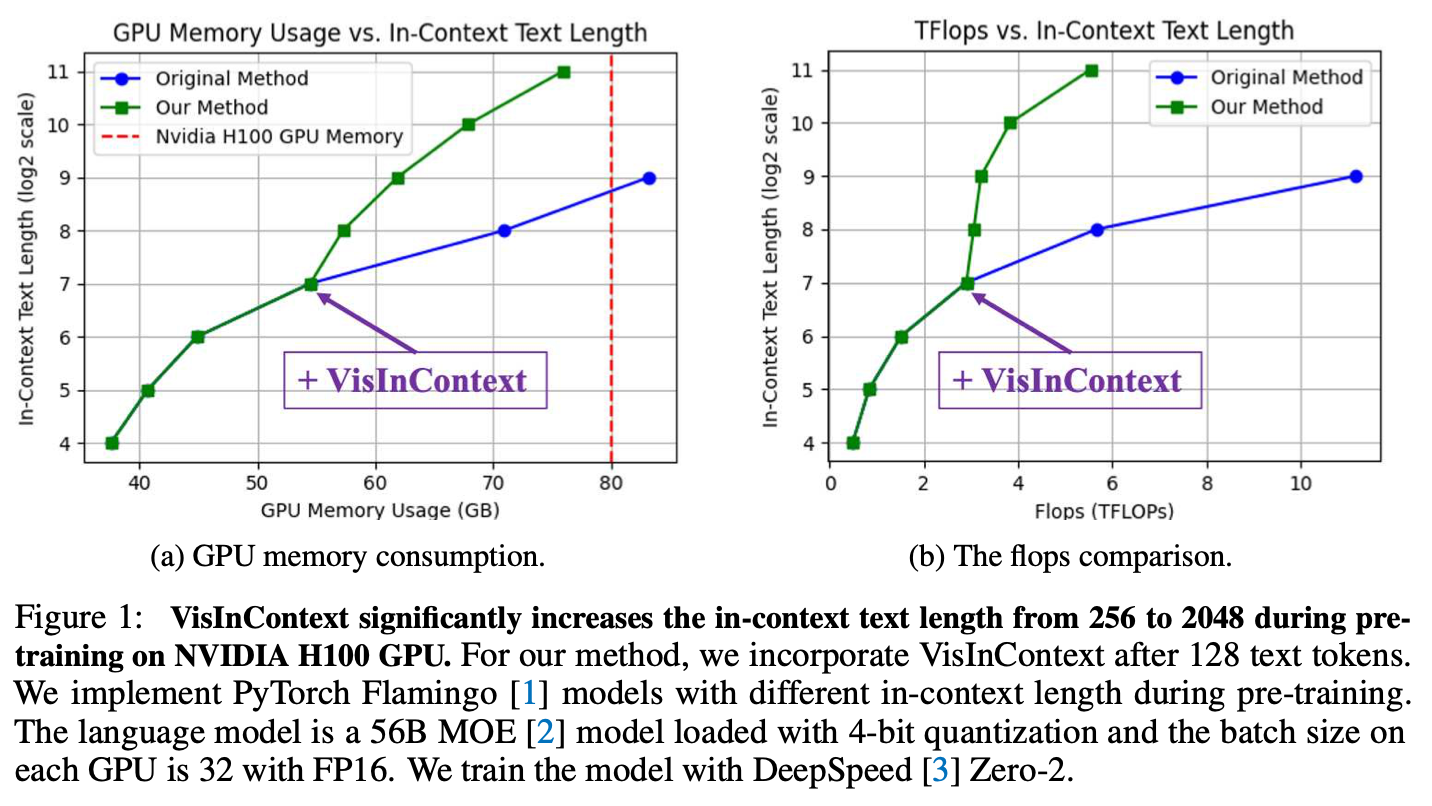
Long-text understanding in LLM is another ideal situation.
Xing et al., NeurIPS 2025 — “Vision-Centric Token Compression in Large Language Models” (VIST):
inspired by a human slow–fast reading circuit: a fast visualized path renders distant context as images for quick semantic extraction; a slow path feeds key text to LLM for deep reasoning.
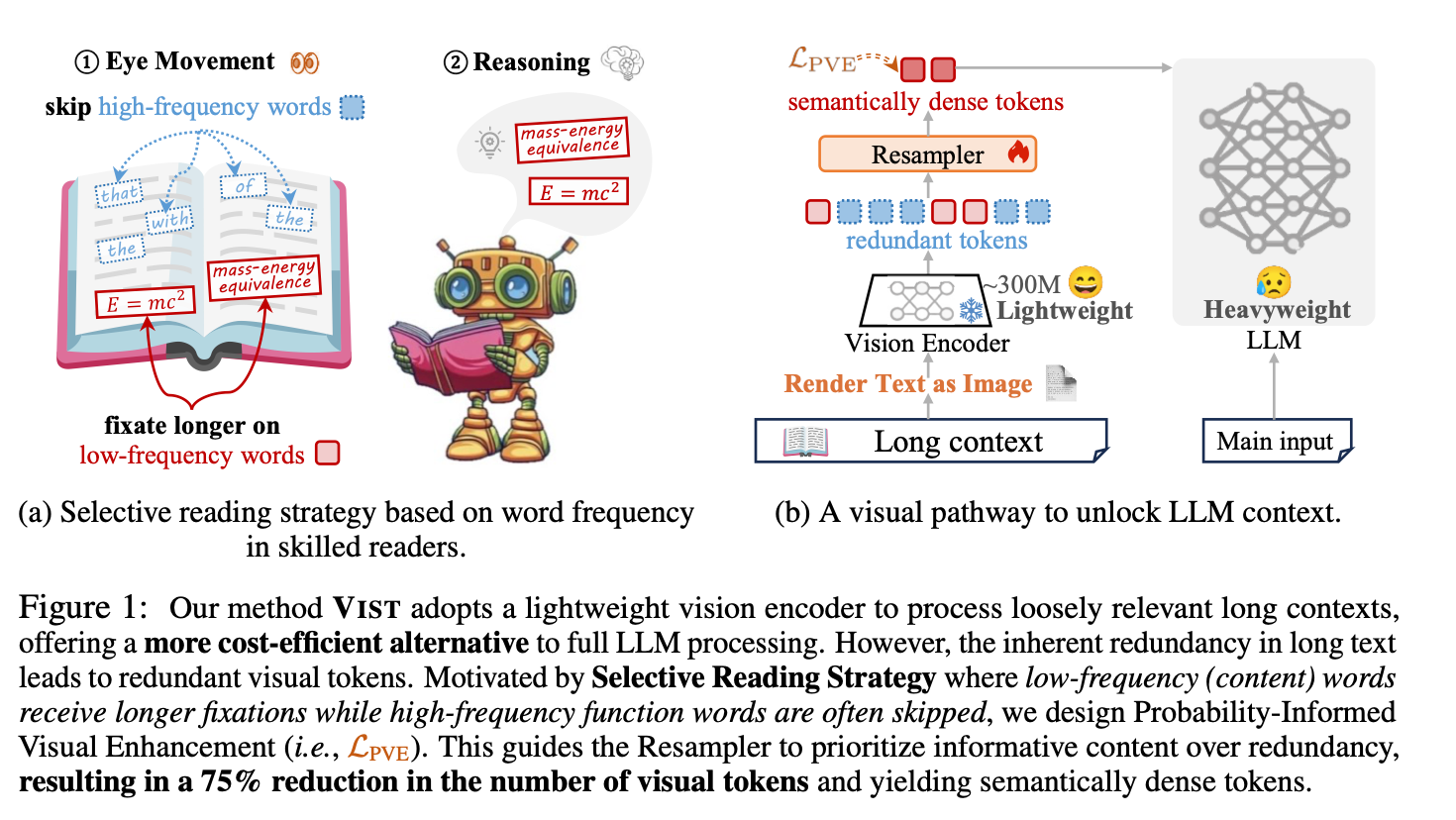
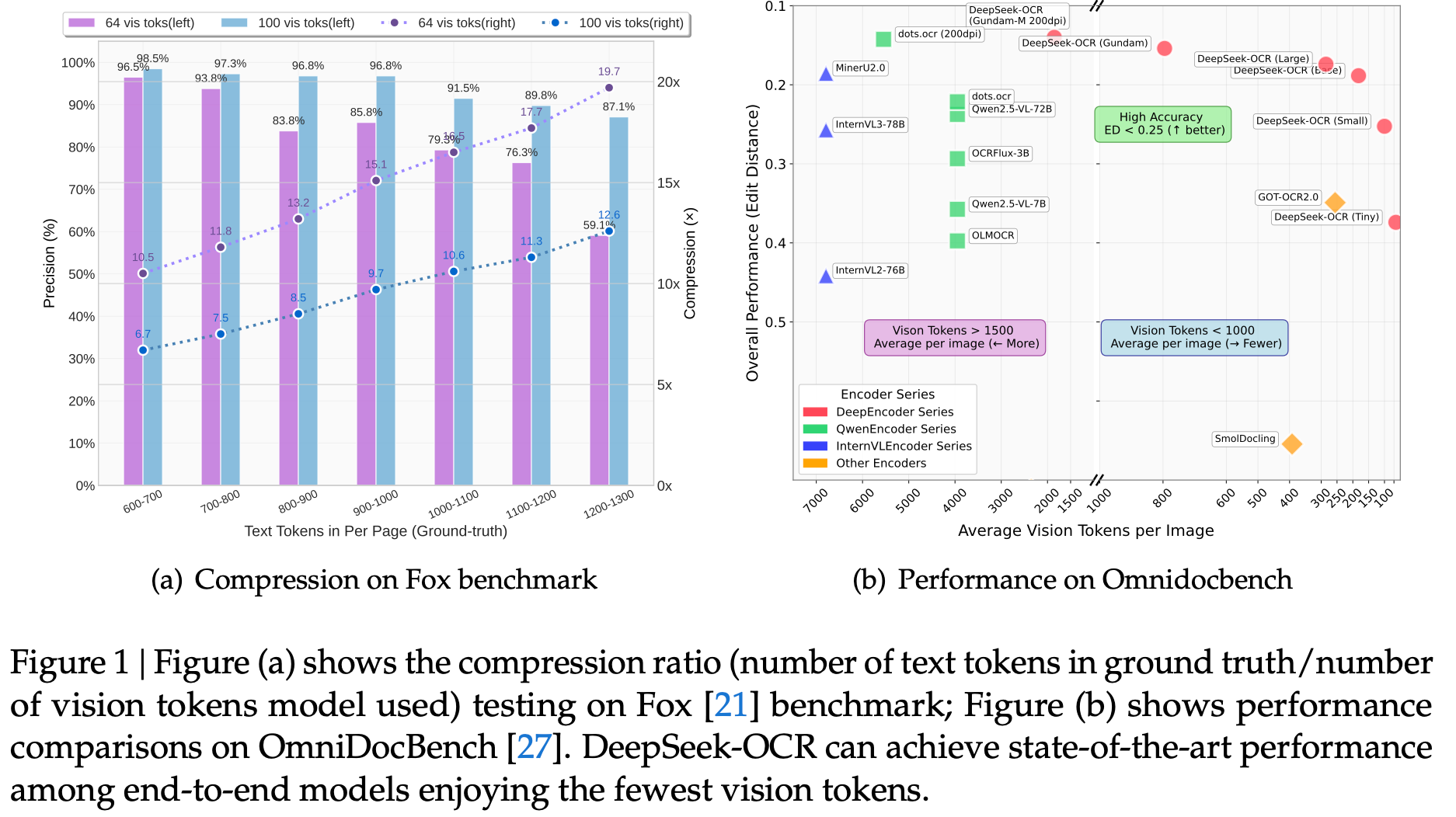
DeepSeek-OCR (Oct 2025): Contextual Optical Compression extends visual-token compression to OCR: compressing thousands of text tokens into a few hundred visual reps, reaching ~97% OCR precision at ~10× compression. DeepSeek-OCR was driven by powerful infrastructure and painstaking large-scale data preparation, enabling the model to scale visual–token compression far beyond prior works.
The convergence of visual perception and language understanding is not a coincidence — it is the next paradigm shift.
4. The Future Ahead: A Vision-centric MLLM
In a truly vision-centric multimodal language model, we may no longer need a traditional tokenizer. The model could read text visually — as humans do — and even generate text as images, unifying perception and generation in the same visual space.
Dense Text Image Generation:
To reach that goal, we must perfect image-based text rendering and long-text visual generation:
TextAtlas5M provides large-scale dense text rendering where captions, documents, and designs are visually represented.

Beyond Words aims to generate text-heavy, information-dense images from natural prompts, pushing multimodal autoregressive models toward true long-text visual generation.
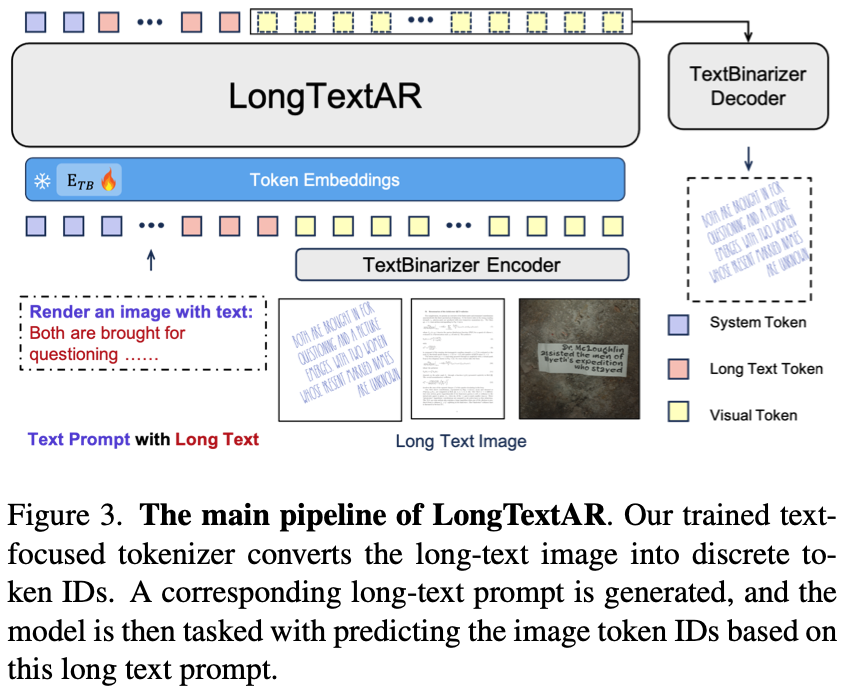
Xing et al, Arxiv25'10 - "SEE THE TEXT: FROM TOKENIZATION TO VISUAL READING", this work extend this idea to more tasks include Classification, and QA.
5. Toward the Next Generation of Vision-centric MLLM
- Text is visual, not merely symbolic.
- Vision is language, not separate.
- Compression is perception, not just engineering.
The ultimate goal is a model that reads, writes, and sees text the way humans do — through the eyes of vision.
People see text. Soon, LLMs & LVMs will too.